























 เพื่อป้องกันข้อมูล Microsoft 365")


 – ขับเคลื่อนแอปพลิเคชันแบบ Gen AI ด้วย Redis Cloud และ Amazon Bedrock")


ทางเว็บ gbhackers.com ได้เผยแพร่ทูลสำหรับย่อยข้อมูลเอกสารของ PDF เพื่อแยกองค์ประกอบต่างๆ สำหรับวิเคราะห์ไฟล์ เพื่อระบุว่าไฟล์ PDF ดังกล่าวมีอันตรายหรือไม่
ทูลนี้มีฟีเจอร์สำคัญมากมายไม่ว่าจะเป็น ตัวโหลดหรือวางออพเจ็กต์และเฮดเดอร์, การดูดข้อมูลส่วนเมต้าดาต้า (เช่น ผู้แต่ง คำอธิบาย), ตัวดูดข้อมูลข้อความจากหน้าต่างๆ แบบเรียงลำดับ, รองรับไฟล์ PDF แบบบีบอัด, รองรับรหัสตัวอักษรแบบ MAC OS Roman ไปจนถึงแบบ Hexa และ Octal, รวมทั้งรองรับมาตรฐาน PSR-0 และ PSR-1
สำหรับการวิเคราะห์ไฟล์ PDF อันตราย หรือไฟล์ที่มีไฟล์ EXE ซ่อนอยู่ภายในอีกทีนั้น
1. ให้เปิด PDF Parser ด้วยคำสั่ง pdf-parser –h
root@kali:~# pdf-parser -h
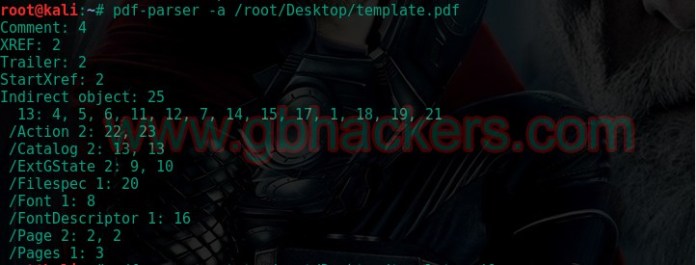
2. จากนั้นจึงตรวจข้อมูลสถิติของเอกสาร PDF ด้วยคำสั่ง pdf-parser -a (ชื่อไฟล์)
root@kali:~# pdf-parser -a /root/Desktop/template.pdf
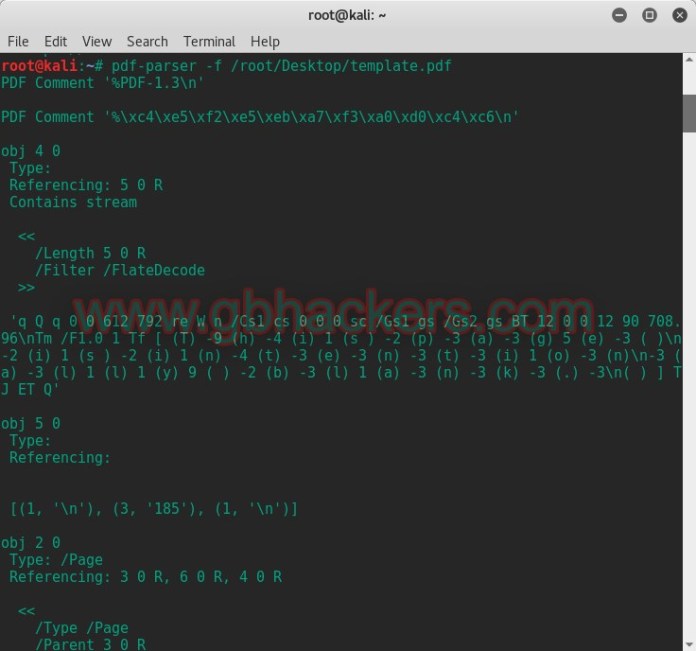
3. แล้วจึงสตรีมข้อมูลเข้ามาผ่านตัวกรองอย่าง FlateDecode,ASCIIHexDecode, ASCII85Decode, LZWDecode,และ RunLengthDecode
root@kali:~# pdf-parser -f /root/Desktop/template.pdf
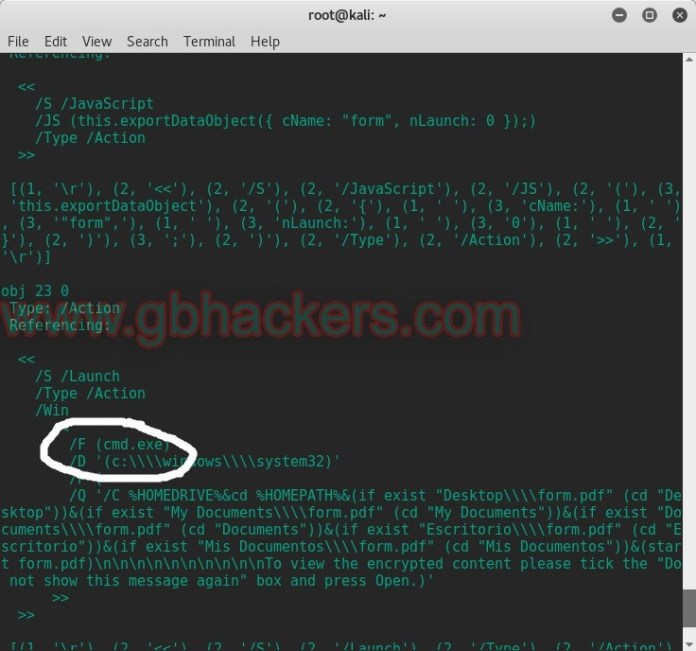
4. สำหรับการเรียกดู Hash ของไฟล์ pdf ให้ใช้คำสั่ง pdf-parser -H (ชื่อไฟล์)
root@kali:~# pdf-parser -H /root/Desktop/template.pdf

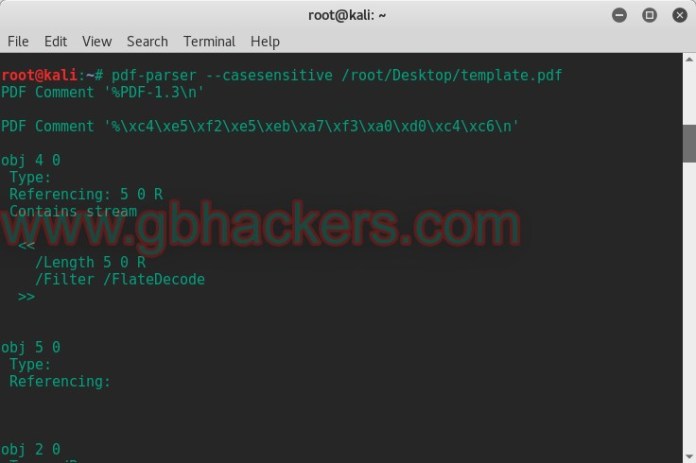
5. รวมทั้งเสิร์ชแบบดูตามตัวอักษรพิมพ์เล็กพิมพ์ใหญ่ด้วยคำสั่ง pdf-parser -casesensitive (ชื่อไฟล์)
root@kali:~# pdf-parser –casesensitive /root/Desktop/template.pdf
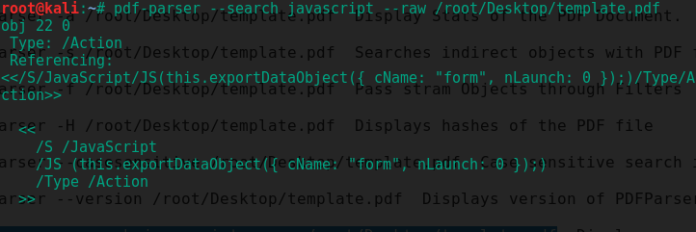
6. หรือสามารถดูดเอาข้อมูลโค้ดจาวาสคริปต์ที่ถูกเพิ่มเข้าไปในเอกสารได้ด้วยคำสั่ง pdf-parser -search javascript -raw (ชื่อไฟล์)
pdf-parser –search javascript –raw /root/Desktop/template.pdf
ลองทำกันดูได้เลย
ที่มา : gbhackers






")









{kind=link}